Ключевое понятие
К большим данным относятся данные из социальных сетей, Интернета вещей, данные с датчиков, а также могут любые другие как структурированные, так и нет. SAP HANA Vora — это решение SAP для обработки больших объемов внешних данных такого типа, которые, как правило, хранятся в среде больших данных, например, Hadoop. Решение SAP HANA Vora упрощает использование больших данных для ускорения операций анализа и принятия решений.
Один из основателей компании Intel, Гордон Мур, в 1975 году предсказал, что вычислительная мощность будет удваивается ежегодно благодаря технологии сжатия в сборке интегрированных микросхем. Одним из неожиданных последствий такого быстрого роста вычислительной мощности стало невероятное увеличение объема данных, ежедневно генерируемых людьми и их интеллектуальными устройствами (например, Интернетом вещей). Стремительный рост количества данных вместе с сопутствующим увеличением вычислительных мощностей намного опережает по скорости темпы использования этих данных. Растущий объем затрудняет интеграцию больших данных в корпоративные данные приложений для более эффективного анализа.
Большие данные обладают следующими признаками: скорость, объем и разнообразие структурированных и неструктурированных данных. Hadoop — одна из платформ для обработки больших данных, которая позволяет менее затратно хранить и анализировать такой объем данных, поскольку платформа Hadoop функционирует, распределяя данные во множестве нод более дешевого стандартного оборудованияПроизводительность в этом случае не страдает, поскольку обработка распределяется по множеству узлов, работающих параллельно. При этом, если необходимо, количество узлов может быть быстро увеличено. Это архитектура экосистемы больших данных Hadoop верхнего уровня, которая зависит от множества узлов.
В 2015 году компания SAP разработала новое решение для анализа больших данных, SAP HANA Vora. Решение SAP HANA Vora оснащено модулем обработки данных в оперативной памяти, который можно интегрировать в экосистему больших данных Hadoop и среду выполнения Apache Spark. Apache Spark — универсальный движок обработки данных в оперативной памяти, полностью совместимый с данными распределенного Hadoop.
SAP HANA Vora предназначена для использования в крупных распределенных файловых системах, обрабатывающих большие данные. Она позволяет повысить производительность благодаря обработке данных в оперативной памяти, а также предоставляет возможности оперативной аналитической обработки (OLAP) для многомерного анализа, включая иерархическую отчетность. Кроме того, Vora оптимизирует интеграцию и ускоряет использование больших данных из сред Hadoop и других решений, например, SAP HANA. Несмотря на то, что решение Hadoop является открытой платформой от Apache, существуют коммерческие распределенные среды Hadoop от различных поставщиков. В настоящее время SAP HANA Vora поддерживается только в следующих инсталляциях:
- Платформа данных Hortonworks (HDP).
- Cloudera Enterprise (CDH).
- MapR.
SAP HANA Vora подключается к общему модулю обработки данных в оперативной памяти Apache Spark. (Сам по себе модуль Apache Spark может функционировать как автономное решение на базе Hadoop, но это не имеет значения для темы данной статьи.) Для интерактивного анализа больших данных SAP HANA Vora использует среду выполнения Apache Spark на платформе Hadoop. Для работы поверх данных Hadoop решению SAP HANA Vora не требуется платформа SAP HANA.
В рассматриваемом здесь сценарии бизнес-случая платформе Hadoop требуется интегрировать большие данные с корпоративными данными в SAP HANA. В этом сценарии SAP HANA Vora упрощает использование больших данных из Hadoop (с помощью среды выполнения Apache Spark) и корпоративных данных из SAP HANA, обеспечивая, таким образом, единую платформу для объединения данных для составного анализа. Благодаря этому специалисты по обработке данных и разработчики могут быстро проанализировать набор данных в Hadoop, объединив его с корпоративными данными из базы данных SAP HANA.
Для этого сценария до появления SAP HANA с пакетом поддержки (SPS) 10 база данных SAP HANA подключалась к большим данным через соединения Open Database Connectivity (ODBC) для Smart Data Access (SDA). Начиная с SPS 10 база данных SAP HANA использует большие данные, подключаясь к платформе Hadoop с помощью контроллера Apache Spark. В версии начиная с SAP HANA SPS 11, SAP HANA Vora с версией 1.0 доступна как еще одна опция. В этой версии для подключения к платформе Hadoop по-прежнему используется контроллер Apache Spark (адаптер Spark-SQL). Однако теперь подключение устанавливается со службами SAP HANA Vora, работающими в среде Hadoop, и не зависит от Apache Spark и хранилища метаданных Hive, как это было ранее (в SPS 10). Таким образом, данные теперь доступны для двустороннего использования — из Hadoop или SAP HANA — в интегрированной среде с SAP HANA и платформой Hadoop.
Архитектура SAP HANA Vora
Среда Hadoop представляет собой кластер, в котором тысячи узлов создают платформу для хранения, обращения и анализа больших структурированных данных и сложных неструктурированных данных. Решение SAP HANA Vora функционирует как еще одна служба в экосистеме Hadoop.
Если вы уже работали на платформе Hadoop, вероятно, вы знакомы с ее архитектурой. Для тех, кто не знаком с Hadoop, ниже приводятся базовые сведения для понимания места SAP HANA Vora в среде Hadoop.
Hadoop представляет собой сочетание множества компонентов с открытым исходным кодом, которые работают совместно для поддержки распределенной обработки больших наборов данных. Данные распределены между множеством узлов в кластере в так называемых распределенных файловых системах Hadoop (HDFS). По сути, узлы являются всего лишь менее затратными системами под управлением Linux. К другим важным компонентам относится YARN, который управляет всеми ресурсами кластера Hadoop, например, выделением памяти; Apache Spark; Zookeeper, который координирует управление всеми службами на платформе Hadoop, и база данных HBase, которая является базой данных Hadoop и работает поверх кластеров с узлами.
Hive SQL, Spark SQL и Pig Scripting — это языки запросов, на которых создаются запросы данных Hadoop из HDFS кластера (рис. 1). Этот инструмент поддерживает распределенную обработку больших структурированных и неструктурированных наборов данных в кластере из нескольких узлов, одновременно работая в тысячах узлов. Apache Ambari (для распределения HDP) используется для предоставления служб в любом числе узлов кластера.
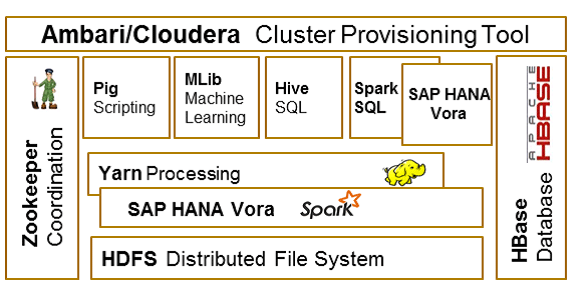
Рис. 1. Обзор среды Hadoop
Полная версия статьи доступна в оригинальном источнике по ссылке sapland.ru
Авторы

Анупам Гупта работает менеджером по практическому внедрению системы Enterprise Performance Management (EPM) в The Principal Consulting (TPC). Его опыт разработки приложений SAP и консультирования по решениям SAP для клиентов из разных стран в области финансового планирования, отчетности и консолидации насчитывает более 10 лет. Анупам имеет обширный опыт консультирования клиентов по вопросам ИТ-стратегии и дорожным картам технологий. Он отвечает за разработку компетенций EPM, основных средств управления знаниями и решений TPC для широкого диапазона продуктов SAP: SAP NetWeaver BW, SAP BusinessObjects, SAP Business Planning and Consolidation и SAP Strategic Enterprise Management.

Васи Венкатесан является главным консультантом компании SAP и уже более 14 лет работает с системами SAP. Он внедрил множество решений SAP Business Warehouse (BW) и бизнес-аналитики (BI), в том числе SAP HANA и решения для озер данных. В компании SAP Васи, в основном, занимается поставкой решений BI для клиентов в сфере розничной торговли и нефтегазовой отрасли, а также участвует в первой разработке и реализации решения с методом учета по розничным ценам. В настоящее время автор работает, прежде всего, с инструментами SAP HANA, SAP BW и SAP BusinessObjects, а также с решениями для обработки больших данных, например, Hadoop.
С автором можно связаться по адресу vasi.venkatesan@sap.com.
Корректура

Дмитрий Буслов рзанимает должность консультанта SAP BI в компании «БДО Юникон Бизнес Солюшнс», Россия. Один из победителей конкурса экспертов SAP BI (SAPLand совместно с компанией SAP CIS) в 2011 г. Сертифицированный консультант C_TBW45_70, а также C_HANAIMP_10. Модератор подфорума HANA на портале sapboard.ru.Основное направление — высокопроизводительная отчетность.
С Дмитрием можно связаться по адресу d.buslov@bdo.ru.
14.07.2017